 Assembler and Interpreter, both are system programs that perform language translation. They accept a computer program in one language and convert it to another language. Although they are quite different in their working process.
Assembler and Interpreter, both are system programs that perform language translation. They accept a computer program in one language and convert it to another language. Although they are quite different in their working process.
Assembler is a system program that accepts assembly language code and converts it to machine language code. On the other hand, the interpreter accepts the source code in a high-level language and translates it into machine language code.
In the case of an assembler, before execution, the source code has to pass through translation, linking and loading. However, in the case of an interpreter, the source code is directly translated.
In the section ahead, we will explore more differences between these two language translators.
Content: Assembler Vs Interpreter
- Comparison Chart
- What is Assembler in Computer?
- What is Interpreter in Computer?
- Similarity Between Assembler and Interpreter
- Key Differences
- Conclusion
Comparison Chart
| Basis for Comparison | Assembler | Interpreter |
|---|---|---|
| Basic | It accepts assembly language code and converts it to a relocatable machine language code. | It translates source code in a high-level language to machine language, instruction by instruction. |
| Input | Low language program (assembly language code) | High-level language program |
| Translation | Translation takes place before program execution. | Translation takes place at the time of execution. |
| Errors | It identifies errors before program execution. | It identifies errors at the time of execution. |
| Executable File | It creates an executable file. | It does not create any executable file. |
| Use Source Code | It uses source code once to create an executable file | It uses source code each time during the execution |
| Memory Requirement | It requires comparatively more memory. | Less memory |
| Speed | Faster | Slower |
What is Assembler in Computer?
Assembler is a system program that translates the assembly language code into a relocatable machine code. The Assembly language code that it accepts is a low-level language code. Though it is close to machine language code, still the system is unable to understand this assembly language code.

Thus, we need an assembler to convert assembly language code to machine language code. During translation, the assembler does not resolve all the external references in the assembly code. These references are later resolved by the linker. So, the assembler is quite fast in translation.
The assembler generates a machine language code in an executable file. Thus it requires memory for the storage of this executable file.
What is Assembly Language?
Assembly language is a low-level programming language. Unlike binary language, we use mnemonics to represent an instruction in assembly language. Thus, it is readable by humans. Assembly language is machine-dependent, so the assembly language differs from machine to machine.
How Does Assembler Work?
The working of an assembler totally depends on how many phases it will be used to convert assembly language code to machine language code.
If it’s a one-pass assembler, it would resolve all the instructions in a single pass and would generate the machine code.
If it’s a two/multi-pass assembler, it will resolve all the instructions in code in two or multiple passes.
Types of Assembler
One-pass Assembler
The one-pass assembler converts the assembly language program to a machine language program in a single pass.
Two/Multi-Pass Assembler
The two-pass assembler converts assembly language code to machine language code in two or multiple passes.
- In the first pass, the assembler processes the pseudo-op instructions, identify symbols and opcodes and stores them in the symbol tables.
- In the second pass, the assembler converts the opcode into a numeric opcode, resolves the pseudo opcode and generates machine code.
Assembler Directives
Assembler directives are the commands that control the operation of the assembler. These commands basically help the assembler in the:
- Identifying the beginning and end of the program
- Assigning storage to the data
- Assigning values to the variables
- Identify the start and end of different segments, macros, procedures etc.
What is Interpreter in Computer?
The interpreter is a language translator that translates a source code in a high-level language to a machine language code. During this translation, the interpreter does not generate any intermediate program. We refer to this intermediate program as the target program. So, compared to other language translators, it takes less memory for storage.
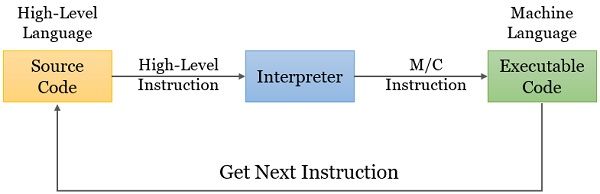
The interpreter line-by-line scans the instructions from the source program and translates them to the machine instruction. Thus, it detects errors in the source program at the time of execution. Error debugging is easier with an interpreter.
The interpreter resolves all the external references in the source code during interpretation. Thus, it is slower.
How Does Interpreter Work?
The interpreter interprets the source program using the interpretation cycle repeatedly. The interpretation cycle analyzes the first statement of the source program, understands its meaning and then performs the corresponding action.
Now in each interpretation cycle, the interpreter analyzes the next statement of the source program, identifies its meaning and performs the corresponding action. The interpreter even resolves the external references during translation. All this incurs substantial overhead on the interpreter making it slow.
The interpreter does not even produce any target program like a compiler or assembler. Thus it requires less memory as compared to other language translators.
Types of Interpreter
- Bytecode Interpreter
The compiler first compiles the source code and converts it into bytecode. Bytecode is not exactly machine code, but it is a compressed and optimized source code form. This bytecode is then interpreted by the interpreter and converted to the machine code. As here we require both compiler and interpreter, we often refer to bytecode interpreters as “compreters”. - Threaded Code Interpreter
Threaded code is a technique that we use to implement virtual machine interpreters. It is similar to a bytecode interpreter but uses pointers to access functions or instructions n the source code. - Abstract Syntax Tree Interpreter
The abstract syntax tree (ATS) represents source code in the form of a tree. This tree conveys the structure of the source code to the interpreter. ATS interpreter interprets the abstract syntax tree to generate a machine code. - Self-Interpreter
This interpreter can interpret themselves. The most popular self-interpreter is a BASIC interpreter. Self-interpreter is created in case no compiler exists for a particular language.
Similarity Between Assembler and Interpreter
- Assembler and interpreter are both system programs.
- Both of them are used to perform language translation.
- Both of them convert their source code to machine language code.
Key Differences Between Assembler and Interpreter
- The assembler accepts the assembly language program and translates it into a relocatable machine language program. On the other hand, the interpreter accepts the source program in a high-level language and translates the program instructions line by line into machine instructions.
- The assembler accepts the assembly language code generated by the compiler. The interpreter accepts source code in a high-level language.
- The assembler translates the assembly code to machine code before the program execution. However, the interpreter translates the source program instructions to machine instructions at the time of program execution.
- The assembler identifies errors in the assembly code before the program execution. Conversely, the interpreter identifies the error in the source program at the time of its execution.
- The assembler generates a relocatable machine language code, an executable file. However, the interpreter does not generate any such file.
- Once the assembler converts the assembly language code to the relocatable machine code, we do not require source code each time during its execution. Whereas the interpreter requires the source code each time during execution as it does not create any executable file for execution.
- As an assembler generates an executable file so, it requires memory space for its storage. On the other hand, interpreters do not create any such file, so it does not require memory for its storage.
- The assembler does not resolve any external references in the source code, so it is faster. While the interpreter resolves all the external references in the source code thus, it is much slower.
Conclusion
So, in this way, assemblers and interpreters differ from each other. We have discussed both of these language translators in detail, along with their types and working.
Leave a Reply