 The major difference between types of parsing techniques top-down and bottom-up parsing is that the top-down parsing follows method to construct a parse tree for an input string which begins at the root and grow towards the leaves. As against, in bottom-up parsing, a reverse method where the parsing starts from the leaves and directed towards the leaves.
The major difference between types of parsing techniques top-down and bottom-up parsing is that the top-down parsing follows method to construct a parse tree for an input string which begins at the root and grow towards the leaves. As against, in bottom-up parsing, a reverse method where the parsing starts from the leaves and directed towards the leaves.
Before understanding the types of parsing, we must know what is parsing and why it’s done. Parsing is the technique of examining a text containing a string of tokens, to find its grammatical structure according to the given grammar.
Now, let us discuss the responsibilities of a parser. The parser receives a string of token from the lexical analyser. When the string of tokens can be generated by the grammar of the source language, then the parse tree can be constructed. Additionally, it reports the syntax errors present in the course thing. After this, the generated parse tree is transferred to the next stage of the compiler.
Content: Top-down Parsing vs Bottom-up Parsing
Comparison Chart
| Basis for comparison | Top-down Parsing | Bottom-up Parsing |
|---|---|---|
| Initiates from | Root | Leaves |
| Working | Production is used to derive and check the similarity in the string. | Starts from the token and then go to the start symbol. |
| Uses | Backtracking (sometimes) | Handling |
| Strength | Moderate | More powerful |
| Producing a parser | Simple | Hard |
| Type of derivation | Leftmost derivation | Rightmost derivation |
Definition of Top-down Parsing
In Top-down parsing, we know that the parse tree is generated in the top to bottom fashion (i.e. from root to leaves). It derives the leftmost string and when the string matches the requirement it is terminated. The top-down parsing is mainly intended to discover the suitable production rules to generate the correct results.
Example
We will understand the top-down parsing process using an example, where the considered grammar is given below:
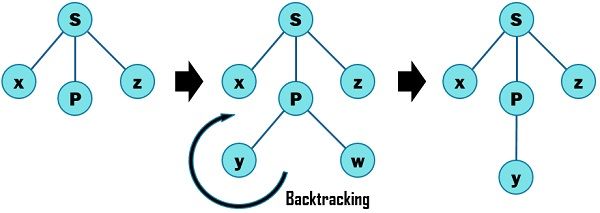
S –> xPz
P –> yw|y
Assume that the input string is “xyz” as shown below, the parse tree of the given input string is generated using the above-given grammar by the following steps of the top-down approach.
- In the first step the leftmost leaf is compared with the first input symbol and it matches. So, the input pointer is shifted to the next symbol. Here, the next symbol is P which is expanded further according to grammar.
- We derive yw from P (P –> yw) using the first production rule, as a result, the produced string doesn’t match the input string as it has additional symbol w. Therefore, we backtrack (go to the previous) to check whether there is another alternative or not. The other production rule that we can use is P –> y, which matches to the input string.
- At last we check for the last terminal z and it also matches the grammar. Hence, the process is ceased and declared that the parsing is completed successfully.
Definition of Bottom-up Parsing
The Bottom-up parsing method is just inverse of top-down where the input string is taken in the first place and then the string is reduced using the grammar. In this process the start symbol is acquired at the end of the process then it halts. As mentioned above the tree is constructed from leaves to the root, and the input symbols are located at the leaf nodes after successful execution of the parsing method.
We have used the term reduction what is actually means? The parser in the process attempts to recognise the RHS of production rule and substitute the corresponding LHS on it, this is known as reduction. Thence, the bottom-up parse tree is constructed from the end leaves, the leaves are further reduced to the internal nodes, and internal nodes are reduced to the root node, as shown in the below-given equation.
Non-terminal for the internal node = Non-terminal ∪ Terminal
Example
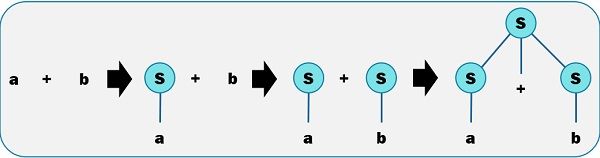
Let us assume the token stream is “a+b” whose parse tree is constructed according to the below-given grammar.
G, S –> S * S | S + S | S – S | a | b
- In the very first step, the input string a + b generates S + B by reducing a to S, using the production S –> a.
- The second reduction produces S + S by reducing b to S, using the production S –> b.
- In the last step the S + S is reduced to S (start symbol), with the help of S –> S + S production.
Key Differences Between Top-down and Bottom-up Parsing
- The top-down parsing starts with the root while bottom-up begin the generation of the parse tree from the leaves.
- Top-down parsing can be done in two ways with backtracking and without backtracking where leftmost derivation is used. On the other hand, the bottom-up parsing uses a shift-reduce method where the symbol is pushed and then popped from the queue. It employs rightmost derivation.
- Bottom-up parsing is more powerful than the top-down parsing.
- It is difficult to produce a bottom-up parser. As against, a top-down parser can be easily structured and formed.
Limitations of top-down parsing
These conditions could hamper the construction of the parser.
- Backtracking: It is a method of expanding non-terminal symbol where one alternative could be selected until any mismatch occurs otherwise another alternative is checked.
- Left recursion: This result in a serious problem where the top down parser could enter an infinite loop.
- Left factoring: Left factoring is used when the suitability of the two alternatives is checked while expanding the non-terminals.
- Ambiguity: Ambiguous grammar creates more than one parse tree of the single string which is not acceptable in top-down parsing and need to be eliminated.
Limitation of bottom-up parsing
The major disadvantage of the bottom up parser is the production of the ambiguous grammar. We know that it generates more than one parse tree which must be eliminated. However, the operator precedence parser in bottom-up parser could also work with the ambiguous grammar.
Conclusion
The parsing methods top-down and bottom-up are differentiated by the process used and type of parser they generate such as the parsing which starts from the roots and expands to the leaves is known as top-down parsing. Conversely, when the parse tree is built from leaves to root then it is bottom-up parser.
Leave a Reply