 The COCOMO 1 and COCOMO 2 are the cost estimation models developed by Barry Boehm for computing the cost of the developing software. Initially, COCOMO basic model was introduced, followed by the enhanced versions of the COCOMO model. The main difference between these COCOMO models is that the COCOMO 1 is completely premised on the linear reuse formula and the hypothetical idea about the stable set of requirements. In contrast, the COCOMO 2 is founded on the non-linear reuse formula, and also provide auto-calibration characteristics.
The COCOMO 1 and COCOMO 2 are the cost estimation models developed by Barry Boehm for computing the cost of the developing software. Initially, COCOMO basic model was introduced, followed by the enhanced versions of the COCOMO model. The main difference between these COCOMO models is that the COCOMO 1 is completely premised on the linear reuse formula and the hypothetical idea about the stable set of requirements. In contrast, the COCOMO 2 is founded on the non-linear reuse formula, and also provide auto-calibration characteristics.
Before the development of a project, it is necessary to find the cost and time needed to develop it efficiently. Previously we didn’t have any method to find the cost, manpower and time going to be required in developing a particular software product. COCOMO model was proposed to solve regarding issue of estimating the relevant factors and mainly the cost. In this article, we are going to discuss COCOMO 1 and COCOMO 2 models.
Content: COCOMO 1 Vs COCOMO 2
Comparison Chart
| Basis for comparison | COCOMO 1 | COCOMO 2 |
|---|---|---|
| Basic | Founded on linear reuse formula | Based on the non-linear reuse formula |
| Size of software stated in terms of | Lines of code | Object points, function points and lines of code |
| Number of submodels | 3 | 4 |
| Cost drivers | 15 | 17 |
| Model framework | Development begins with the requirements assigned to the software. | It follows a spiral type of development. |
| Data points | 63 projects referred | 161 projects referred |
| Estimation precision | Offers estimates of effort and schedule. | Supplies estimates that represent one standard derivation nearly the most likely estimate. |
Definition of COCOMO 1
COCOMO model was first introduced in the year of 1980s by Barry W. Boehm, which was the most straightforward model proposed to compute the software cost, development time, average team size, and effort required to develop a software project. This model uses the number of lines of code (in thousand) delivered.
The software projects are classified into three types, in order to estimate effort accurately.
- Organic Projects: The organic type of projects are not very bulky and includes the 50 KDLOC (a kilo of delivered lines of codes or less). It requires the pre-experienced team along with a deep understanding of the software project. These types of projects are easily developed and are not time bounded and the example of such projects are business system, payroll management system, inventory management systems, etcetera.
- Embedded Projects: These kinds of projects are quite complex in nature and involves 300 KDLOC or more. The team required to make these projects are not needed to have a lot of experience, novice or inexperienced developers can also work in these projects. However, while developing these projects user need to follow stringent constraints (hardware, software, people, deadline) and it must satisfy the user’s strict requirements. The example of these projects is software systems employed in the avionics and military tech.
- Semi-detached Projects: As the name suggests, this category lies between organic and embedded projects. Similarly, the complexity of these projects lies between the organic and embedded projects where less than 300 K lines of codes could be delivered. It requires an averagely experienced person and a medium deadline to produce the product. These projects could involve operating systems, database design, compiler design, and so on.
Standard COCOMO formulae to estimate software development effort
Effort = a1 * (KLOC) a2 PM
T dev = b1 * (Effort) b2 Months
- Where E is the effort employed in person-months.
- T Dev is the development time in chronological months.
- KLOC means Kilo lines of code for the project.
- P is the total number of persons required to complete the project.
The coefficients a1, b1, a2 and b2 for three modes are as given below.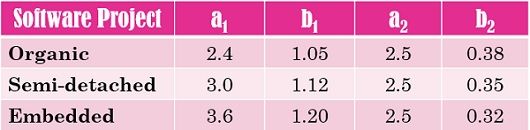
Definition of COCOMO 2
COCOMO 1 model is absolutely based on the waterfall model, but due to acquiring the object-oriented approach in the software development process, the COCOMO 1 does not produce accurate results. So, to overcome the limitations of COCOMO 1, COCOMO 2, was developed.
The prior aim of the COCOMO 2 model is to generate the support capabilities for amending the model constantly and provides quantitative analytic structure, techniques and tools. It is also capable of examining the effects of software technology improvements in the expense of software development life cycle.
COCOMO 2 estimation models
The estimation models included in the COCOMO 2 are application composition model, early design model, reuse model and post-architecture model.
- Application composition model: This model is intended to use with the reusable components and generate estimates of prototype development and works on the basis of object points. The model is more suitable for the prototype system development. To estimate the total effort the following steps are followed.
- Calculate object points– The objects points are nothing but the number of the object instances which could be needed to develop screens, reports or 3GL (Third Generation Language) components. Screens are categorised based on the number of views and sources, whereas reports are classified in terms of sections and sources.
- Classification of objects instances– These instances can be distinguished into simple, medium or difficult complexity level depending on the criteria given by Boehm.
- Allotting complexity weight to each object instance– The object instances are assigned a numeric value, which shows the effort required to implement an instance of the desired complexity level.
- Identify the object points count– The number of instances and its weight are multiplied for every object and to acquire the object points count these objects are added.
- Calculate new object points (NOP)– NOP can be calculated by considering the percentage of reuse to be obtained in the software.
NOP = (Object points count)x[(100 – %reuse)/100] - Derive productivity (PROD) rate– Productivity rate is computed by using the relation of NOP and Effort as given below.
PROD = NOP/Effort
The application composition model provides the productivity rates according to the developers’ experience and development environment maturity as displayed in the below-given table.
- Estimate effort– The estimated effort is expressed by the equation.
Effort = NOP/PROD
- Early design model: The model used at the designing phase of the system design after acquiring the requirements. Its estimates are created on the basis of function points which are then translated into several lines of source code. The estimates at this stage are founded on the basic formula for algorithm models:
Effort = A x Size B x M
Here, A is a constant whose value must be 2.94 while the value of B reflects the increment in the effort and varies in the range of 1.1 to1.24 which depends on the scaling factors like precedentedness, development flexibility, team cohesion, etcetera. The M depends on the cost drivers or project characteristics. - Reuse model: It is a model which compute the effort needed to combine reusable components and/or program code which is spontaneously produced by design or program conversion tools. There are two types of reused codes that are black-box and white-box code. The black box code is used when there is no understanding of code and modification performed in it. Conversely, the white box is employed when the new code is integrated. The effort required to integrate this code is estimated as follows:
E = (ALOC x AT/100)/ATPROD
Where:
ALOC = Number of LOC that have to be adapted in a component
AT = Adapted code percentage that is automatically generated
ATPROD = Productivity in combining the code
The value of ATPROD can be 2400 LOC per month. - Post-architecture model: After designing the system architecture, the more precise software estimate can be made. This model is considered as the most detailed model among all of the models which can produce the most detailed and accurate estimate. The effort of a post-architecture model can be computed in the following way:
E = A x size B x M
Here the A and B constants are calculated in the similar as explained above but the value of M multiplier depends on the attributes like a product, computer, project and personal attributes.
Key Differences Between COCOMO 1 and COCOMO 2
- The COCOMO 1 model was founded on the linear reuse formula where the structure is a simply procedural and stable set of requirements are predicted. On the contrary, the COCOMO 2 is based on the non-linear reuse model which provides features like auto-calibration and reuse of the code.
- In COCOMO 1 the size of the software is expressed by lines of code. As against, COCOMO 2 provides more factors to express the software size such as object points, line of code and function points too.
- There are three number of submodels in COCOMO 1 (i.e, basic, intermediate, advanced) while in COCOMO 2, it is 4 (viz, application development model, early design model, reuse model and post-architectural model).
- COCOMO 2 uses 17 numbers of cost drivers. As against, COCOMO 1 uses 15 cost drivers.
- There are no scaling factors used in the COCOMO 1, while COCOMO 2 employs the scaling factors in order to estimate effort.
- COCOMO 2 can mitigate the level of risk as compared to COCOMO 1 model.
Conclusion
The COCOMO models were developed in different era according to the advances in programming and software development and engineering techniques the COCOMO models have also been evolved. The COCOMO 2 model is more comprehensive as compared to COCOMO 1. As the COCOMO 1 was devised for the softwares developed using procedural languages and constructs while in present scenarios most of the languages and software are developed using object-oriented paradigms for which COCOMO 2 is more suitable.
Leave a Reply