 The cloud computing works in a consolidated manner, and the big data comes under the cloud computing. The crucial difference between cloud computing and big data is that cloud computing is used to handle the huge storage capacity, (big data) through extending the computing and storage resources. On the other side, big data is nothing but an enormous amount of the unstructured, redundant and noisy data and information from which the useful knowledge have to be extracted. To perform the above function the cloud computing technology provides various flexible and techniques to tackle a magnificent amount of the data.
The cloud computing works in a consolidated manner, and the big data comes under the cloud computing. The crucial difference between cloud computing and big data is that cloud computing is used to handle the huge storage capacity, (big data) through extending the computing and storage resources. On the other side, big data is nothing but an enormous amount of the unstructured, redundant and noisy data and information from which the useful knowledge have to be extracted. To perform the above function the cloud computing technology provides various flexible and techniques to tackle a magnificent amount of the data.
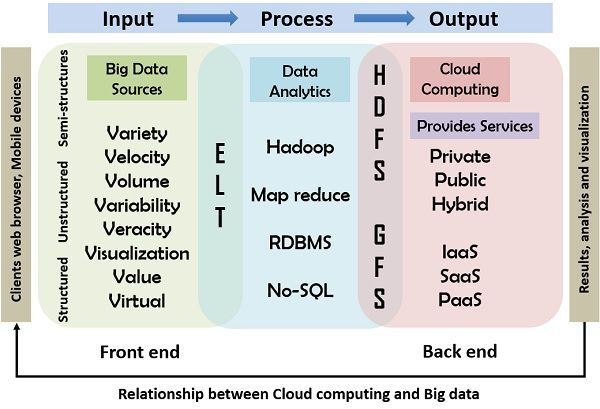
It involves the input, processing and output model which is explained below; the diagram illustrates the relationship between cloud computing and big data in detail.
Content: Cloud Computing and Big Data
Comparison Chart
| Basis for comparison | Cloud Computing | Big Data |
|---|---|---|
| Basic | On-demand services are provided by using integrated computer resources and systems. | Extensive set of structured, unstructured, complex data forbidding the traditional processing technique to work on it. |
| Purpose | Enable the data to be stored and processed on the remote server and accessed from any place. | Organization of the large volume of data and information to the extract hidden valuable knowledge. |
| Working | distributed computing is used to analyse the data and produce more useful data. | Internet is used to provide the cloud-based services. |
| Advantages | Low maintenance expense, centralised platform, provision for backup and recovery. | Cost effective parallelism, scalable, robust. |
| Challenges | Availability, transformation, security, charging model. | Data variety, data storage, data integration, data processing, and resource management. |
Definition of Cloud Computing
Cloud computing provides an integrated platform of services to store and retrieve any amount of data, at any time, from anywhere on demand using high-speed internet. Cloud is a broad set of terrestrial servers dispersed across the internet to store, manage and process the data. The cloud computing is developed so that the developers easily implement the web-scale computing. The evolution of the internet has brewed the cloud computing model as the internet is the foundation of the cloud computing. To make the cloud computing efficiently work we need the high-speed internet connection. It offers a flexible environment, where the capacity and capabilities can be added dynamically, and used according to the pay per use strategy.
The cloud computing has some essential properties that are resource pooling, on-demand self-service, broad network access, measured service and rapid elasticity. There are four types of cloud – public, private, hybrid and community.
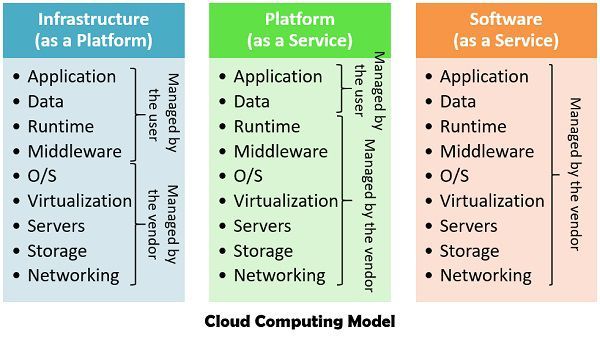
There are basically three cloud computing models – Platform as a Service (Paas), Infrastructure as a Service (Iaas), Software as a Service (Saas), which uses hardware as well as software services.
- Infrastructure as a Service – This service is used for delivering the infrastructure, which includes storage processing power and virtual machines. It implements virtualisation of resources on the basis of service level agreement (SLA’s).
- Platform as a Service – It comes above the IaaS layer, which provides programming and run-time environment to enable the users to deploy the cloud applications.
- Software as a Service – It delivers the applications to the client that directly run on the cloud provider.
Definition of Big Data
The data turns into big data with the increase in volume, variety, velocity, beyond the abilities of the IT systems, which in turn generate difficulty in storing, analysing and processing the data. Some organisation have developed the equipment and expertise to deal with this type of massive amount of structured data, but the exponentially increasing volumes and swift flow of data cease the ability to mine it and to generate actionable intelligence promptly. This voluminous data cannot be stored in the regular devices and dispersed in the distributed environment. Big data computing is an initial concept of data science which concentrates on multidimensional information mining for scientific discovery and business analytics on large-scale infrastructure.
The fundamental dimensions of the big data are volume, velocity, variety and veracity which are also aforementioned above, later two more dimensions are evolved that are variability and value.
- Volume – Signifies the increasing size of data which is already problematic to process and store it.
- Velocity – It is the instance in which the data is captured and the speed of flow of the data.
- Variety – The data does not present in a single form always, there are various forms of the data, for example – text, audio, image and video.
- Veracity – It referred to as the reliability of the data.
- Variability – It describes the trustworthiness, complexity and inconsistencies produced in the big data.
- Value – The original form of the content may not be much useful and productive, so the data is analysed, and high valued data is discovered.
Key Differences Between Cloud Computing and Big Data
- The cloud computing is the computing service delivered on demand by using computing resources dispersed over the internet. On the other hand, the big data is a massive set of computer data, including structured, unstructured, semi-structured data which cannot be processed by the traditional algorithms and techniques.
- The cloud computing provides a platform to the users to avail services such as Saas, Paas, and Iaas, on demand and it also charges for the service according to use. In contrast, the primary objective of big data is to extract the hidden knowledge and patterns from a humongous collection of the data.
- High-speed internet connection is the essential requirement for the cloud computing. As against, big data uses distributed computing in order to analyse and mine the data.
Relationship between the Cloud computing and Big data
The diagram shown below illustrates the relation and working of the cloud computing with big data. In this model, the primary input, processing and output computing model is used as a reference in which the big data is inserted in the system using the input devices such as mouse, keyboard, cell phones, and other smart devices. The second stage of processing includes the tools and techniques used by the cloud to provide the services. At last the result of the processing is delivered to the users.
Conclusion
The Cloud computing technology provides a suitable and compliant framework for the big data through ease of use, access to resources, low cost in resource usage on supply and demand, and also minimises the use of solid equipment utilised in handling the big data. Both cloud and big data emphasize on increasing the value of a company while decreasing the investment cost.
M Irfan says
Love the way how you explain both of term.