 Classification and Clustering are the two types of learning methods which characterize objects into groups by one or more features. These processes appear to be similar, but there is a difference between them in context of data mining. The prior difference between classification and clustering is that classification is used in supervised learning technique where predefined labels are assigned to instances by properties, on the contrary, clustering is used in unsupervised learning where similar instances are grouped, based on their features or properties.
Classification and Clustering are the two types of learning methods which characterize objects into groups by one or more features. These processes appear to be similar, but there is a difference between them in context of data mining. The prior difference between classification and clustering is that classification is used in supervised learning technique where predefined labels are assigned to instances by properties, on the contrary, clustering is used in unsupervised learning where similar instances are grouped, based on their features or properties.
When the training is provided to the system, the class label of training tuple is known and then tested, this is known as supervised learning. On the other hand, unsupervised learning does not involve training or learning, and the training sample is not known previously.
Content: Classification Vs Clustering
Comparison Chart
| Basis for comparison | Classification | Clustering |
|---|---|---|
| Basic | This model function classifies the data into one of numerous already defined definite classes. | This function maps the data into one of the multiple clusters where the arrangement of data items is relies on the similarities between them. |
| Involved in | Supervised learning | Unsupervised learning |
| Training sample | Labeled data is provided. | Unlabeled data provided. |
Definition of Classification
Classification is the process of learning a model that elucidate different predetermined classes of data. It is a two-step process, comprised of a learning step and a classification step. In learning step, a classification model is constructed and classification step the constructed model is used to prefigure the class labels for given data.
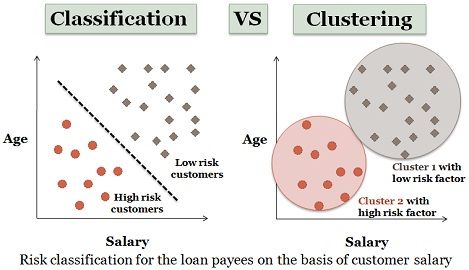
For example, in a banking application, the customer who applies for a loan may be classified as a safe and risky according to his/her age and salary. This type of activity is also called supervised learning. The constructed model can be used to classify new data. The learning step can be accomplished by using already defined training set of data. Each record in the training data is associated with an attribute referred to as a class label, that signifies which class the record belongs to. The produced model could be in the form of a decision tree or in a set of rules.
A decision tree is a graphical depiction of the interpretation of each class or classification rules. Regression is the special application of classification rules. Regression is useful when the value of a variable is predicted based on the tuple rather than mapping a tuple of data from a relation to a definite class. Some common classification algorithms are decision tree, neural networks, logistic regression, etc.
Definition of Clustering
Clustering is a technique of organising a group of data into classes and clusters where the objects reside inside a cluster will have high similarity and the objects of two clusters would be dissimilar to each other. Here the two clusters can be considered as disjoint. The main target of clustering is to divide the whole data into multiple clusters. Unlike classification process, here the class labels of objects are not known before, and clustering pertains to unsupervised learning.
In clustering, the similarity between two objects is measured by the similarity function where the distance between those two object is measured. Shorter the distance higher the similarity, conversely longer the distance higher the dissimilarity.
Another example of clustering, there are two clusters named as mammal and reptile. A mammal cluster includes human, leopards, elephant, etc. On the other hand, reptile cluster includes snakes, lizard, komodo dragon etc. The tools mainly used in cluster analysis are k-mean, k-medoids, density based, hierarchical and several other methods.
Key Differences Between Classification and Clustering
- Classification is the process of classifying the data with the help of class labels. On the other hand, Clustering is similar to classification but there are no predefined class labels.
- Classification is geared with supervised learning. As against, clustering is also known as unsupervised learning.
- Training sample is provided in classification method while in case of clustering training data is not provided.
Conclusion
Classification and clustering are the methods used in data mining for analysing the data sets and divide them on the basis of some particular classification rules or the association between objects. Classification categorizes the data with the help of provided training data. On the other hand, clustering uses different similarity measures to categorize the data.
opera says
great article thanks
Cybermart says
Best article.
amirhosseinnazemi67 says
thank you.
it is concise, precise and informative.
Abin Varghese says
Thank you so much for the clarification.
Waqar says
Awesome explanation……
Palani says
Thanks for the explanation, its simple and clear.
Sarat says
Great Article